

1 はじめに
1.1 調査目的 43
1.2 市場の定義
1.2.1 包含と除外 44
1.3 市場範囲 45
1.3.1 市場セグメンテーション 45
1.3.2 考慮した年数 48
1.4 通貨 49
1.5 利害関係者 49
2 調査方法 50
2.1 調査データ 50
2.1.1 二次データ 51
2.1.2 一次データ 51
2.1.2.1 一次プロファイルの内訳 52
2.1.2.2 主要業界インサイト 52
2.2 市場ブレークアップとデータ三角測量 53
2.3 市場規模の推定 54
2.3.1 トップダウンアプローチ 54
2.3.2 ボトムアップアプローチ
2.4 市場予測 59
2.5 リサーチの前提 60
2.6 調査の限界 62
3 エグゼクティブサマリー 63
4 プレミアムインサイト
4.1 AIトレーニングデータセット市場におけるプレーヤーにとっての魅力的な機会 71
4.2 AIトレーニングデータセット市場:上位3つのデータモダリティ別 72
4.3 北米:AIトレーニングデータセット市場、
アノテーションタイプ別、エンドユーザー別 72
4.4 AIトレーニングデータセット市場:地域別 73
5 市場概要と業界動向 74
5.1 はじめに 74
5.2 市場ダイナミクス 74
5.2.1 推進要因 75
5.2.1.1 多様かつ継続的に更新されるマルチモーダルデータセットに対する生成AIモデルへのニーズの高まり 75
5.2.1.2 会話AIにおける多言語データセットの利用の増加 75
5.2.1.3 自律走行車のための高品質ラベル付きデータへの需要の高まり 76
5.2.1.4 レアイベントシミュレーションにおける合成データの採用増加 76
5.2.2 制約事項 77
5.2.2.1 著作権侵害によるウェブスクレイピングデータの法的リスク 77
5.2.2.2 HIPAAコンプライアンスによる高品質医療データセットへのアクセス制限 77
5.2.3 機会 78
5.2.3.1 多様な分野における専門的なデータ注釈サービスへの需要の高まり 78
5.2.3.2 学習データ増強のための合成データ生成とプライバシー保護技術 78
5.2.3.3 企業向けソリューション向けにカスタマイズされたAIデータセットと専用フォーマットの作成 79
5.2.4 課題 79
5.2.4.1 データの品質と関連性の問題 79
5.2.4.2 多様なデータセット形式と一貫性のないアノテーション手法 79
5.3 AIトレーニングデータセットの進化 80
5.4 サプライチェーン分析 82
5.5 エコシステム分析 84
5.5.1 データ収集ソフトウェアプロバイダー 86
5.5.2 データラベリングとアノテーションプラットフォームプロバイダー 87
5.5.3 合成データプロバイダー 87
5.5.4 データ増強ツールプロバイダー 87
5.5.5 既製データセットプロバイダー 87
5.5.6 AIトレーニングデータセットサービスプロバイダー 88
5.6 投資と資金調達のシナリオ 88
5.7 AIトレーニングデータセット市場におけるジェネレーティブAIの影響 91
5.7.1 画像認識のためのデータ補強 92
5.7.2 NLPのための合成テキスト生成 92
5.7.3 音声・音声データ合成 92
5.7.4 模擬ユーザー対話データ 92
5.7.5 データセットにおけるバイアス緩和 92
5.7.6 予測モデルのシナリオテスト 92
5.8 ケーススタディ分析 93
5.8.1 ケーススタディ1:クリックワーカーが自動車システムのAIトレーニングデータセットを強化し、音声認識精度を向上 93
5.8.2 ケーススタディ 2: appen、110言語の包括的なAIトレーニングデータセットでmicrosoft translatorを強化 93
5.8.3 ケーススタディ3:Cogito Tech LLC、AIによる大動脈弁データセットで心臓外科手術を強化 94
5.8.4 ケーススタディ4:superannotateを活用したヒンジヘルスの成功による疼痛軽減のためのAIトレーニングデータセットの強化 94
5.8.5 ケーススタディ5:アウトリーチ社がラベルスタジオでAIトレーニングを強化 95
5.8.6 ケーススタディ6:エンコード、データ品質と効率性を向上させる手術ビデオアノテーションの主要課題に対応 96
5.9 技術分析 96
5.9.1 主要テクノロジー 97
5.9.1.1 データのラベリングとアノテーション 97
97 5.9.1.2 合成データ生成 97
5.9.1.3 データ増強 97
5.9.1.4 ヒューマンインザループ(HITL)フィードバックシステム 98
5.9.1.5 能動学習 98
5.9.1.6 データのクレンジングと前処理 98
5.9.1.7 バイアスの検出と緩和 99
5.9.1.8 データセットのバージョン管理と管理 99
5.9.2 補足技術
5.9.2.1 クラウドストレージとデータレイク 99
5.9.2.2 MLOpsとモデル管理 100
5.9.2.3 データガバナンス 100
5.9.2.4 機械学習フレームワーク 100
5.9.3 隣接テクノロジー 101
5.9.3.1 連携学習 101
5.9.3.2 データ処理のためのエッジAI 101
5.9.3.3 差分プライバシー 101
5.9.3.4 AutoML 102
5.9.3.5 トランスファー学習 102
5.10 規制の状況 102
5.10.1 規制機関、政府機関、その他の組織 103
5.10.2 規制 AIトレーニングデータセット 107
5.10.2.1 北米 107
5.10.2.1.1 AI権利章典の青写真(米国) 107
5.10.2.1.2 自動意思決定に関する指令(カナダ) 107
5.10.2.2 欧州 108
5.10.2.2.1 英国のAI規制白書 108
5.10.2.2 AI 規制法(ドイツ) 108
5.10.2.2.3 デジタル共和国法(フランス) 108
5.10.2.2.4 個人情報保護法(イタリア) 109
5.10.2.2.5 デジタルサービス法(スペイン) 109
5.10.2.2.6 オランダデータ保護局(Autoriteit Persoonsgegevens)ガイドライン 109
5.10.2.2.7 スウェーデン国家貿易委員会 AI ガイドライン 110
5.10.2.2.8 デンマークデータ保護庁(Datatilsynet)の AI 勧告 110
5.10.2.2.9 人工知能 4.0(AI 4.0)プログラム – フィンランド 110
5.10.2.3 アジア太平洋 111
5.10.2.3.1 個人データ保護法案(PDPB)とAI国家戦略(NSAI)-インド 111
5.10.2.3.2 官民データ活用推進基本法とAIガイドライン-日本 111
5.10.2.3.3 新世代人工知能発展計画・AI倫理指針-中国 111
5.10.2.3.4 知能情報化枠組み法 – 韓国 112
5.10.2.3.5 AI倫理フレームワーク(オーストラリア)及びAI戦略(ニュージーランド) 112
5.10.2.3.6 モデル AI ガバナンスフレームワーク(シンガポール) 113
5.10.2.3.7 国家AIフレームワーク(マレーシア) 113
5.10.2.3.8 AIロードマップ(フィリピン) 113
5.10.2.4 中東・アフリカ 114
5.10.2.4.1 サウジアラビアデータ・人工知能庁(SDAIA)規制 114
5.10.2.4.2 UAE国家AI戦略2031 114
5.10.2.4.3 カタール国家AI戦略 114
5.10.2.4.4 国家人工知能戦略(2021-2025)-トルコ 115
5.10.2.4.5 アフリカ連合(AU)のAIフレームワーク 115
5.10.2.4.6 エジプトの人工知能戦略 115
5.10.2.4.7 クウェート国家開発計画(新クウェートビジョン 2035) 116
5.10.2.5 ラテンアメリカ 116
5.10.2.5.1 ブラジルの一般データ保護法(LGPD) 116
5.10.2.5.2 私的当事者の保有する個人データの保護に関する連邦法(メキシコ) 116
5.10.2.5.3 アルゼンチン 個人データ保護法(PDPL)及びAI倫理フレームワーク 117
5.10.2.5.4 チリのデータ保護法及び国家AI政策 117
5.10.2.5.5 コロンビアのデータ保護法(Law 1581)とAI倫理ガイドライン 117
5.10.2.5.6 ペルーの個人データ保護法と国家AI戦略 118
5.11 特許分析 118
5.11.1 方法論 118
5.11.2 出願特許(文書タイプ別) 118
5.11.3 イノベーションと特許出願 119
5.12 価格分析 123
5.12.1 価格設定データ:オファリング別 124
5.12.2 価格データ:製品タイプ別 124
5.13 主要な会議とイベント(2024-2025年) 125
5.14 ポーターの5つの力分析 126
5.14.1 新規参入の脅威 127
5.14.2 代替品の脅威 128
5.14.3 供給者の交渉力 128
5.14.4 買い手の交渉力 128
5.14.5 競合の激しさ 128
5.15 主要ステークホルダーと購買基準 129
5.15.1 購買プロセスにおける主要ステークホルダー 129
5.15.2 購入基準 130
5.16 顧客ビジネスに影響を与えるトレンド/混乱 131
6 AIトレーニングデータセット市場(オファリング別) 132
6.1 はじめに 133
6.1.1 オファリング AIトレーニングデータセット市場の促進要因 133
6.2 データセットの作成 134
6.2.1 堅牢なAIアプリケーション開発の鍵となるデータセット作成 134
6.3 データセットの販売 135
6.3.1 倫理的なデータ販売によるAI開発用データの収益化 135
7 AIトレーニングデータセット市場(データセット作成別) 137
7.1 はじめに 138
7.1.1 データセット作成:AIトレーニング用データセット市場の促進要因 138
7.2 データセット作成ソフトウェア 140
7.2.1 データセット作成ソフトウェアは様々な分野のイノベーションを促進 140
7.2.2 データ収集ソフトウェア 141
7.2.2.1 ウェブスクレイピングツール 142
7.2.2.2 データソーシングAPI 143
7.2.2.3 クラウドソーシング・プラットフォーム 144
7.2.2.4 センサーデータ収集ソフトウェア 145
7.2.3 データのラベリングとアノテーション 146
7.2.3.1 画像アノテーション 147
7.2.3.2 テキストアノテーション 148
7.2.3.3 ビデオアノテーション 149
7.2.3.4 音声アノテーション 151
7.2.3.5 3Dデータアノテーション 152
7.2.4 合成データ生成ソフトウェア 153
7.2.5 データ拡張ソフトウェア 154
7.3 データセット作成サービス 155
7.3.1 最適なaiモデルアライメントのためのカスタマイズデータ作成サービス 155
7.3.2 データ収集サービス 156
7.3.3 データ注釈・ラベリングサービス 157
7.3.4 データ検証サービス 158
8 AIトレーニングデータセット市場(データセット販売別) 160
8.1 はじめに 161
8.1.1 データセット販売:AIトレーニングデータセット市場の促進要因 161
8.2 既製(OTS)データセット 162
162 8.2.1 スケーラビリティと配布の容易さがAiトレーニング用OTSデータセットの魅力 163
8.3 データセットマーケットプレイス 164
8.3.1 データセットマーケットプレイスは重要なリソースへのアクセスを民主化することで AI イノベーションを加速 164
9 AIトレーニング用データセット市場(アノテーションタイプ別) 165
9.1 はじめに 166
9.1.1 アノテーションタイプ: AIトレーニングデータセット市場の促進要因 166
9.2 標識済みデータセット 168
9.2.1 高品質なラベル付け済みデータセットが様々な分野のAI開発を加速 168
9.3 ラベルなしデータセット 169
9.3.1 ロバストなAIモデル学習を可能にするラベルなしデータセット 169
9.4 合成データセット 170
9.4.1 生成モデルの進歩により合成データセットの質が向上 170
10 AIトレーニングデータセット市場(データモダリティ別) 172
10.1 はじめに 173
10.1.1 データの種類 AIトレーニング用データセット市場の促進要因 173
10.2 テキスト 174
10.2.1 モデル精度を高めるために、企業は多様なラベル付きテキストデータセットのキュレーションを優先 174
10.2.2 テキスト分類 175
10.2.3 チャットボット 176
10.2.4 センチメント分析 177
10.2.5 文書解析 178
10.2.6 その他のテキストデータのモダリティ 179
10.3 画像 181
10.3.1 深層学習技術、特に畳み込みニューラルネットワークの進歩がAI開発における画像データの役割を高める 181
10.3.2 物体検出 182
10.3.3 顔認識 183
10.3.4 医療用画像 184
10.3.5 衛星画像 185
10.3.6 その他の画像データモダリティ 186
10.4 音声・音声 187
10.4.1 音声認識技術の普及が多様で高品質な音声データセットの需要を後押し 187
10.4.2 音声認識
10.4.3 音声分類 189
10.4.4 音楽生成 190
10.4.5 音声合成 191
10.4.6 その他の音声・音声データモダリティ 192
10.5 ビデオ 194
10.5.1 動画コンテンツの可能性を活用しようとする企業による高品質なラベル付き動画データセットの需要急増 194
10.5.2 行動認識 195
10.5.3 自律走行 196
10.5.4 ビデオ監視 197
10.5.5 動画コンテンツのモデレーション 198
10.5.6 その他の映像データモダリティ 199
10.6 マルチモーダル 200
10.6.1 マルチモーダルデータセットへの需要の高まりがAIアプリケーションの革新と進歩を後押し 200
10.6.2 音声からテキストへの変換 201
10.6.3 コンテンツ推薦 202
10.6.4 ビジュアル質問応答(VQA) 203
10.6.5 マルチモーダル分析 204
10.6.6 その他のマルチモーダリティ 205
11 AIトレーニングデータセット市場(タイプ別) 207
11.1 はじめに 208
11.1.1 タイプ別 AIトレーニングデータセット市場の促進要因 208
11.2 ジェネレーティブAI 210
11.2.1 ジェネレーティブAIは多様なトレーニングデータセットを通じて産業全体の創造性に革命を起こす 210
11.2.2 LM評価 211
11.2.3 ラグ最適化 212
11.2.4 LMの微調整 214
11.2.5 会話エージェント 215
11.2.6 コンテンツの作成 216
11.2.7 コード生成 217
11.2.8 その他の生成AI 218
11.3 その他のAI 219
11.3.1 エンタープライズAIアプリケーションにおけるNLPとコンピュータビジョンの役割の高まりがその他のAIデータセットの需要を押し上げる 219
11.3.2 自然言語処理(NLP) 220
11.3.2.1 テキスト分類 221
11.3.2.2 名前付きエンティティ認識(NER) 222
11.3.2.3 センチメント分析 223
11.3.2.4 文書の構文解析と抽出 224
11.3.3 コンピュータビジョン 225
11.3.3.1 画像分類 226
11.3.3.2 物体検出 227
11.3.3.3 ビデオ解析 228
11.3.3.4 光学的文字認識(OCR) 229
11.3.4 予測分析 230
11.3.4.1 時系列予測 232
11.3.4.2 異常検知 233
11.3.4.3 顧客行動予測 234
11.3.4.4 リスクスコアリングと管理 235
11.3.5 推薦システム 236
11.3.5.1 製品とコンテンツの推奨 237
11.3.5.2 パーソナライズされたマーケティングと広告 238
11.3.5.3 協調フィルタリング 239
11.3.6 音声・音声処理 240
11.3.6.1 音声認識 241
11.3.6.2 音声分類 242
11.3.6.3 音声コマンド認識 243
11.3.6.4 音声からテキストへの転写 244
11.3.7 その他のタイプ 245
12 AIトレーニングデータセット市場:エンドユーザー別 246
12.1 はじめに 247
12.1.1 エンドユーザー:AIトレーニングデータセット市場の促進要因 247
12.2 BFSI 249
12.2.1 金融機関はaiトレーニングデータセットを活用して不正検知とリスク管理を強化 249
12.2.2 銀行 250
12.2.3 金融サービス 251
12.2.4 保険 252
12.3 通信 253
12.3.1 AIを活用したインテリジェント・システムでパフォーマンスと顧客サービスを向上させる通信事業者 253
12.4 政府・防衛 254
12.4.1 AIのトレーニングデータセットが国家安全保障と防衛活動の進歩を促進 254
12.5 ヘルスケア・ライフサイエンス 256
12.5.1 AIトレーニングデータセットが精密医療と診断における画期的なブレークスルーを先導 256
12.6 製造業 257
12.6.1 AIトレーニングデータセットは自動化と予知保全で製造業の効率化を促進 257
12.7 小売・消費財 258
12.7.1 小売業はAI主導のレコメンデーションと最適化されたサプライチェーンでパーソナライズされた顧客体験を強化 258
12.8 ソフトウェア&テクノロジープロバイダー 259
259 12.8.1 ソフトウェア・技術プロバイダーがAIのトレーニングデータセットを最先端のソリューションに活用し、イノベーションが加速 259
12.8.2 クラウド・ハイパースケーラー 260
12.8.3 基盤モデル/LLMプロバイダー 261
12.8.4 AIテクノロジープロバイダー 262
12.8.5 IT及びIT対応サービスプロバイダー 263
12.9 自動車 264
12.9.1 実世界の運転行動や状況を捉えたAIのトレーニングデータセットに後押しされた自律走行車開発の急速な進展 264
12.10 メディア&エンターテインメント 265
12.10.1 AIトレーニングデータセットはメディア、ゲーム、エンターテインメント業界のコンテンツ制作のイノベーションを促進 265
12.11 その他のエンドユーザー 266
13 AIトレーニングデータセット市場(地域別) 268
13.1 はじめに 269
13.2 北米 270
13.2.1 北米:AIトレーニングデータセット市場の促進要因 271
13.2.2 北米:マクロ経済見通し 271
13.2.3 米国 280
13.2.3.1 AIアルゴリズムの精度と性能を向上させるための大規模かつ多様なデータセットへの様々な分野の企業の依存が市場を牽引 280
13.2.4 カナダ 281
13.2.4.1 AI投資の利益を最大化するために関係者からの知見収集に注力する政府が市場を牽引 281
13.3 欧州 282
13.3.1 欧州: AIトレーニングデータセット市場の促進要因 282
13.3.2 欧州: マクロ経済見通し 283
13.3.3 英国 291
13.3.3.1 様々な分野からの高品質データと革新的ソリューションに対する需要の高まりが市場を牽引 291
13.3.4 ドイツ 292
13.3.4.1 産業界の需要、政府の支援、データプライバシー規制が市場を牽引 292
13.3.5 フランス 293
13.3.5.1 競争力維持のためのハイテク企業や新興企業によるAIソリューション採用の増加 293
13.3.6 イタリア 294
13.3.6.1 データ収集・管理の進歩により、企業は様々なAIアプリケーションに合わせた多様なデータセットにアクセス可能に 294
13.3.7 スペイン 295
13.3.7.1 政府の戦略的イニシアティブと業界のイノベーションが市場を牽引 295
13.3.8 オランダ 296
13.3.8.1 倫理的AIへの注力とデジタルインフラの拡大により、高品質で多様な訓練用データセットの需要が加速 296
13.3.9 その他の欧州 297
13.4 アジア太平洋 298
13.4.1 アジア太平洋地域:AIトレーニング用データセット市場の促進要因 298
13.4.2 アジア太平洋地域:マクロ経済見通し 298
13.4.3 中国 308
13.4.3.1 様々な分野からの学習モデル用高品質データへの需要増加が市場を牽引 308
13.4.4 日本 309
13.4.4.1 政府の支援政策と企業の戦略的イニシアティブが市場を牽引 309
13.4.5 インド 310
13.4.5.1 様々な分野でのAIソリューション需要の増加が市場を牽引 310
13.4.6 韓国 311
13.4.6.1 AI導入の増加と高品質データセットの必要性が市場を牽引 311
13.4.7 オーストラリア 312
13.4.7.1 高品質データと倫理基準の需要が市場を牽引 312
13.4.8 シンガポール 313
13.4.8.1 情報通信メディア開発庁(IMDA)のようなイニシアチブはデータリテラシーとAIの利用を促進 313
13.4.9 その他のアジア太平洋地域 314
13.5 中東・アフリカ 315
13.5.1 中東・アフリカ:AIの訓練用データセット市場の促進要因 315
13.5.2 中東・アフリカ:マクロ経済見通し 315
13.5.3 中東 324
13.5.3.1 UAE 325
13.5.3.1.1 予測分析と疾病検出のための膨大な医療データセットを構築する医療セクターの取り組みが市場を牽引 325
13.5.3.2 サウジアラビア 326
13.5.3.2.1 サウジアラビアのオープンデータプラットフォームの立ち上げと世界的ハイテク企業との提携でAI訓練用データセット開発が加速 326
13.5.3.3 カタール 327
13.5.3.3.1 ストリーミングデータに特化した新興企業への戦略的投資が市場を牽引 327
13.5.3.4 トルコ 328
13.5.3.4.1 政府のイニシアティブと様々な分野からの高品質データセットへの需要増加が市場を牽引 328
13.5.3.5 その他の中東地域 329
13.5.4 アフリカ 330
13.5.4.1 様々な分野でのAI応用の可能性の高まりが市場を牽引 330
13.6 ラテンアメリカ 331
13.6.1 中南米:AIトレーニングデータセット市場の促進要因 331
13.6.2 ラテンアメリカ:マクロ経済見通し 332
13.6.3 ブラジル 340
13.6.3.1 ITとヘルスケア分野の成長が市場を牽引 340
13.6.4 メキシコ 341
13.6.4.1 政府のイニシアティブと民間投資が市場を牽引 341
13.6.5 アルゼンチン 342
13.6.5.1 政府の透明性イニシアティブと新興企業支援が市場を牽引 342
13.6.6 その他のラテンアメリカ 343
14 競争環境 344
14.1 概要 344
14.2 主要プレーヤーの戦略/勝利への権利(2021-2024年) 344
14.3 収益分析、2019-2023年 347
14.4 市場シェア分析、2023年 349
14.4.1 市場ランキング分析 350
14.5 製品比較分析 352
14.5.1 AWSセージメーカー(AWS) 353
14.5.2 AIデータプラットフォーム(appen) 353
14.5.3 SAMAプラットフォーム(SAMA) 353
14.5.4 データエンジン、Scale Gen AIプラットフォーム(Scale AI) 353
14.5.5 イメリット・プラットフォーム(イメリット) 353
14.6 2024年の企業評価と財務指標 353
14.7 企業評価マトリックス:主要プレーヤー(2023年) 355
14.7.1 スター企業 355
14.7.2 新興リーダー 355
14.7.3 浸透型プレーヤー 355
14.7.4 参加企業 355
14.7.5 企業フットプリント:主要プレーヤー(2023年) 357
14.7.5.1 企業フットプリント 357
14.7.5.2 地域別フットプリント 358
14.7.5.3 オファリングのフットプリント 359
14.7.5.4 データモダリティフットプリント 360
14.7.5.5 エンドユーザーのフットプリント 361
14.8 企業評価マトリクス:新興企業/SM(2023年) 362
14.8.1 進歩的企業 362
14.8.2 対応力のある企業 362
14.8.3 ダイナミックな企業 362
14.8.4 スタートアップ・ブロック 362
14.8.5 競争ベンチマーキング:新興企業/SM(2023年) 364
14.8.5.1 主要新興企業/中小企業の詳細リスト 364
14.8.5.2 主要新興企業/中小企業の競争ベンチマーク 366
14.9 競争シナリオ 367
14.9.1 製品の発売と機能強化 367
14.9.2 取引 370
15 会社プロファイル 371
15.1 紹介 371
15.2 主要プレーヤー 371
…
…
16 隣接市場と関連市場 422
16.1 はじめに 422
16.2 データ注釈・ラベリング市場 422
16.2.1 市場の定義 422
16.2.2 市場の概要 422
16.2.2.1 データ注釈・ラベリング市場、コンポーネント別 423
16.2.2.2 データ注釈・ラベリング市場:データタイプ別 424
16.2.2.3 データ注釈・ラベリング市場:展開タイプ別 424
16.2.2.4 データ注釈・ラベリング市場:組織規模別 425
16.2.2.5 データ注釈とラベリング市場:注釈タイプ別 426
16.2.2.6 データ注釈とラベリング市場:用途別 427
16.2.2.7 データ注釈とラベリング市場:業種別 429
16.2.2.8 データ注釈とラベリング市場:地域別 430
16.3 合成データ生成市場 431
16.3.1 市場の定義 431
16.3.2 市場の概要 431
16.3.2.1 合成データ生成市場:提供製品別 431
16.3.2.2 合成データ生成市場:データタイプ別 432
16.3.2.3 合成データ生成市場:用途別 433
16.3.2.4 合成データ生成市場:垂直方向別 434
16.3.2.5 合成データ生成市場:地域別 435
17 付録 437
17.1 ディスカッションガイド 437
17.2 Knowledgestore: Marketsandmarketsの購読ポータル 443
17.3 カスタマイズオプション 445
17.4 関連レポート 445
17.5 著者の詳細 446
❖ 世界のAIトレーニングデータセット市場に関するよくある質問(FAQ) ❖
・AIトレーニングデータセットの世界市場規模は?
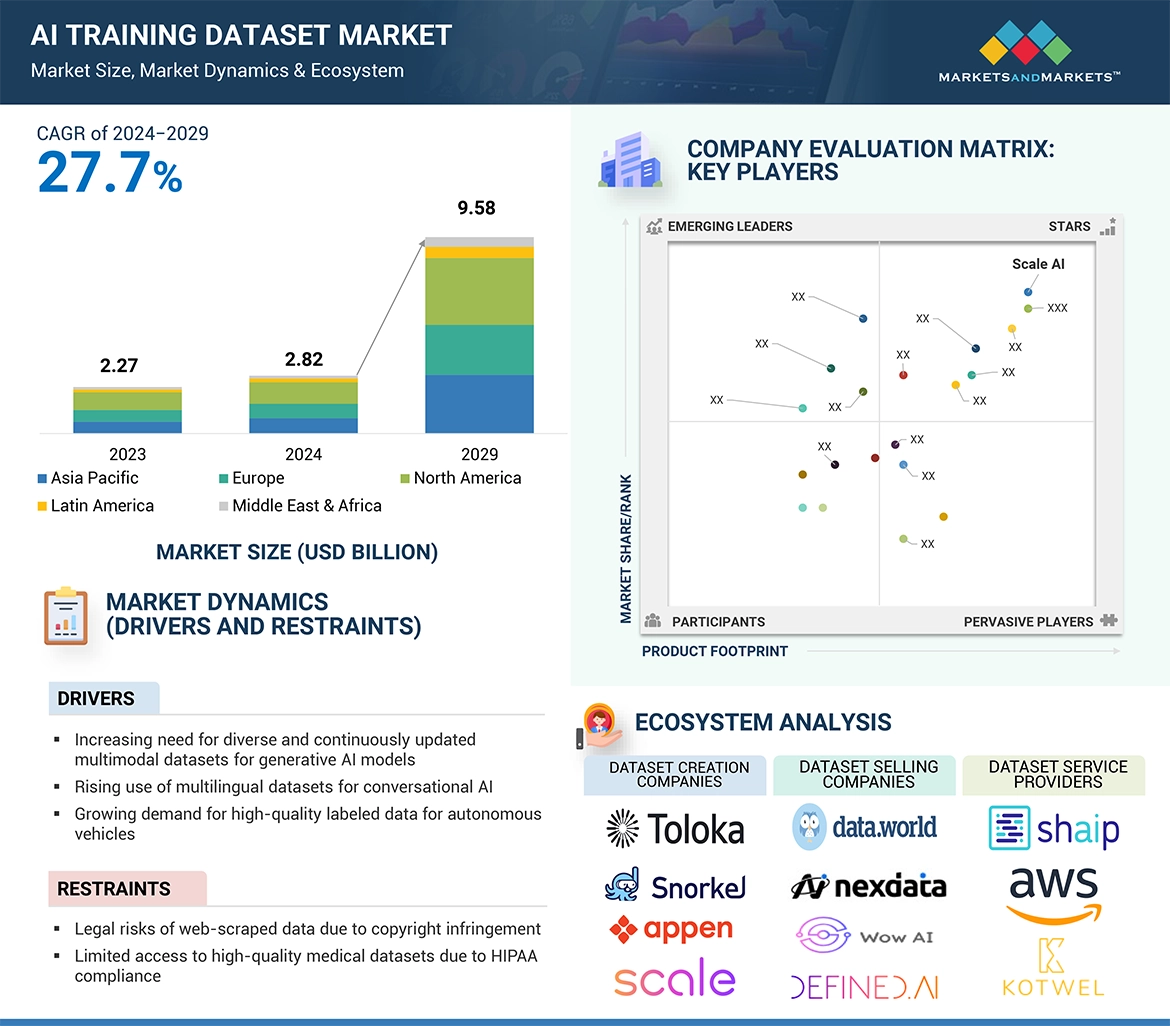
→MarketsandMarkets社は2024年のAIトレーニングデータセットの世界市場規模を28.2億米ドルと推定しています。
・AIトレーニングデータセットの世界市場予測は?
→MarketsandMarkets社は2029年のAIトレーニングデータセットの世界市場規模を95.8億米ドルと予測しています。
・AIトレーニングデータセット市場の成長率は?
→MarketsandMarkets社はAIトレーニングデータセットの世界市場が2024年~2029年に年平均27.7%成長すると予測しています。
・世界のAIトレーニングデータセット市場における主要企業は?
→MarketsandMarkets社は「Google (US), IBM (US), AWS (US), Microsoft (US), NVIDIA (US), Snorkel (US), Gretel (US), Shaip (US), Clickworker (US), Appen (Australia), Nexdata (US), Bitext (US), Aimleap (US), Deep Vision Data (US), Cogito Tech (US), Sama (US), Scale AI (US), Lionbridge Technologies (US), Alegion (US), TELUS International (Canada), iMerit (US), Labelbox (US), V7Labs (UK), Defined.ai (US), SuperAnnotate (US), LXT (Canada), Toloka AI (Netherlands), Innodata (US), Kili technology (France), HumanSignal (US), Superb AI (US), Hugging Face (US), CloudFactory (UK), FileMarket (Hong Kong), TagX (UAE), Roboflow (US), Supervise.ly (Estonia), Encord (UK), TransPerfect (US), Keylabs (Israel), and Data.world (US)など ...」をグローバルAIトレーニングデータセット市場の主要企業として認識しています。
※上記FAQの市場規模、市場予測、成長率、主要企業に関する情報は本レポートの概要を作成した時点での情報であり、納品レポートの情報と少し異なる場合があります。









