❖本調査レポートの見積依頼/サンプル/購入/質問フォーム❖
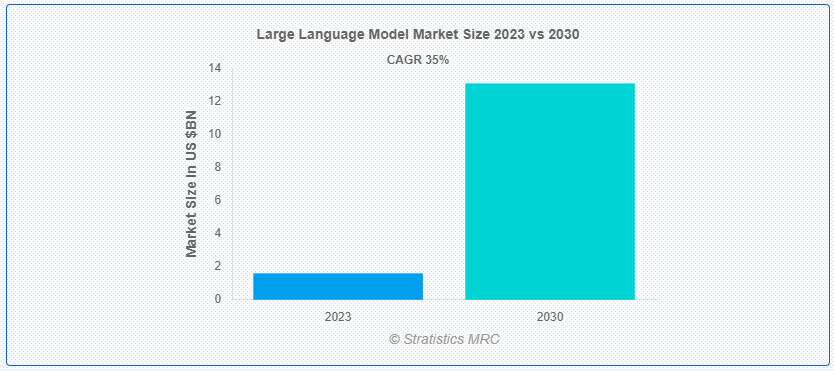
Stratistics MRCによると、世界の大規模言語モデル市場は2023年に16億ドルを占め、予測期間中の年平均成長率は35.0%で、2030年には130.8億ドルに達すると予測されている。大規模言語モデル(LLM)は、学習させた膨大なデータに基づいて人間のようなテキストを理解し、生成するように設計された人工知能の一種である。GPT-3のようなこれらのモデルは、ディープラーニングアーキテクチャ、特にトランスフォーマー上に構築され、印象的なスケールでテキストを処理し、生成することを可能にする。LLMは翻訳、要約、質問応答など様々な言語タスクに優れており、ベンチマークテストではしばしば人間か超人的なパフォーマンスを達成している。LLMは訓練されたデータからパターンと関係性を学習し、幅広いトピックにわたって首尾一貫した、文脈に関連した応答を生成することができます。
市場のダイナミクス:
ドライバー:
AIと機械学習の進歩
AIと機械学習の進歩により、大規模言語モデル(LLM)市場は、これらのモデルの能力と性能を向上させることで推進されている。アルゴリズム、データ処理、計算能力における飛躍的な進歩により、LLMは現在、前例のない精度と一貫性で人間のようなテキストを理解し、生成することができる。このような進歩により、自然言語処理からコンテンツ生成、翻訳に至るまで、さまざまな分野で応用されている。さらに、LLMのスケーラビリティと効率性も向上し、顧客サービスの自動化、データ分析、パーソナライズされたコンテンツの作成など、さまざまなタスクに活用できるようになりました。
拘束:
バイアスと公平性
大規模言語モデルにおけるバイアスと公平性の制約とは、その適用において公平で偏りのない結果を保証することに関係する。これには、モデルの学習に使用されるデータ内に内在するバイアスを特定し、軽減することが含まれます。バイアスに対処するには、データの前処理、アルゴリズムの調整、学習データセットにおける多様な表現などのテクニックが必要です。公平性の抑制は、LLMアプリケーション、特に雇用、貸し出し、コンテンツモデレーションのようなセンシティブな領域において、差別的な結果を防ぐことを目的としている。これらの制約を実装するには、社会におけるLLMの責任ある公平な展開を促進するために、倫理学、社会学、コンピュータサイエンスを含む学際的なアプローチが必要である。
チャンスだ:
コンテンツ生成とパーソナライゼーション
大規模言語モデル市場は、コンテンツ生成とパーソナライゼーションに大きな機会を提供している。人間のようなテキストを理解し、生成する能力を持つLLMは、ジャーナリズムからマーケティングまで、さまざまな業界のコンテンツ作成を自動化することができる。さらに、LLMは個人の嗜好、行動、属性に合わせてコンテンツを調整することで、パーソナライズされた体験を可能にする。このレベルのカスタマイズは、ユーザーのエンゲージメントと満足度を高め、コンバージョン率とブランド・ロイヤルティを向上させます。さらに、LLMはリアルタイムのデータに基づいてコンテンツを動的に適応させ、関連性と適時性を確保することができます。これらの機能を活用することで、企業はコンテンツ制作を効率的に拡張しながら、ターゲット性の高いメッセージを視聴者に届けることができます。
脅威だ:
雇用の転換
大規模言語モデルの出現は、従来人間が行っていた様々な作業を自動化する能力により、雇用を奪う大きな脅威となっている。LLMは膨大な量のテキストを迅速に処理できるため、コンテンツ作成、翻訳、カスタマーサービスなどの役割を代替できる可能性がある。企業が効率化のためにLLMを採用するにつれ、これらの分野における人間の労働需要が減少するリスクがある。この置き換えは、特に反復的または定型的な認知作業を伴う職務の雇用喪失につながる可能性がある。このシフトに対応するためには、LLMと競合するのではなく、LLMの能力を補完するような職務への転換やスキルアップが必要になるかもしれない。
Covid-19の影響:
COVID-19の大流行により、さまざまな分野で大規模言語モデル(LLM)の需要が大幅に加速した。リモートワークやデジタルトランスフォーメーションが必須となる中、企業はタスクの自動化、顧客サービスの強化、業務の合理化において、LLMへの依存度を高めている。この需要の急増により、LLMの研究開発への投資が増加し、医療、金融、教育などの業界全体で採用が進んでいる。しかし、パンデミックによるサプライチェーンの混乱や経済の不確実性も、LLMメーカーや開発者に課題を突きつけた。
予測期間中、サービス分野が最大となる見込み
大規模言語モデル市場のサービス分野は、いくつかの要因によって力強い成長を遂げている。効率と意思決定の改善におけるLLMの価値がますます認識されるにつれ、これらのモデルを実装し、特定のビジネスニーズに合わせてカスタマイズするための専門サービスに対する需要が高まっている。LLMテクノロジーは複雑であるため、継続的なサポートとメンテナンスが必要となり、コンサルティング、トレーニング、マネージド・サービスのニーズが高まっている。さらに、LLMがさまざまな業界で不可欠になるにつれ、サービス・プロバイダーはヘルスケアや金融など、特定の分野に特化した専門知識を含むサービスを提供するようになり、市場の成長をさらに後押ししている。
データ分析およびビジネスインテリジェンス分野は、予測期間中に最も高いCAGRが見込まれている。
データ分析およびビジネス・インテリジェンス分野の成長は、高度なデータ処理および解釈能力に対する需要の高まりが原動力となっている。LLMは、膨大なデータセットから洞察を引き出すための強力なツールを提供し、企業がより正確かつ効率的にデータ主導の意思決定を行うことを可能にする。各業界の企業が競争優位のためにデータを活用することの価値を認識するにつれ、データ分析とビジネスインテリジェンスのためのLLMの採用が増加しています。LLMの自然言語処理技術の進化は、複雑なデータを理解・解釈する能力を高め、市場の成長をさらに促進している。
最もシェアの高い地域:
北米における大規模言語モデル市場の成長は、この地域に複数のハイテク大手や主要なAI研究機関が存在し、言語モデリング技術の革新と開発を促進していることに起因している。医療、金融、カスタマーサービスなど、さまざまな分野で自然言語処理アプリケーションの需要が高まっていることが、LLMの採用を促進している。北米は、クラウド・コンピューティングとデータセンターの堅牢なインフラを誇り、LLMの展開と拡張性を促進している。さらに、熟練した労働力の存在と、AIの研究開発を支援する政府の好意的な政策が、同地域のLLM市場の成長をさらに後押ししている。
CAGRが最も高い地域:
アジア太平洋地域では近年、大規模言語モデル(LLM)の導入と成長が著しい。この成長の背景には、この地域の技術インフラの増加、金融、医療、電子商取引などさまざまな業界におけるAI主導のソリューションに対する需要の急増、熟練したAI人材のプール増加など、いくつかの要因がある。AIの研究開発促進を目的とした政府の取り組みが、アジア太平洋地域におけるLLM市場の拡大にさらに拍車をかけている。さらに、この地域の文化的多様性と広大な言語環境は、LLMが十分に対応できる独自の課題を提示しており、LLMの普及を後押ししている。
市場の主要プレーヤー
大規模言語モデル市場の主要プレーヤーには、AI21 Labs、Alibaba、Amazon、Anthropic、Baidu、Cohere、Crowdworks、Google、Huawei、Meta、Microsoft、Naver、NEC、OpenAI、Technology Innovation Institute (TII)、Tencent、Yandexなどがある。
主な進展
2024年4月、グーグルは現在、アンドロイド・ユーザー向けに一元化された位置情報共有機能の開発に取り組んでいる。Google Location Sharing」として知られるこの新機能は、最近Google Play Servicesのアップデートで発見された。この開発の主な目的は、ユーザーのGoogleアカウントに関連付けられているすべてのアクティブな位置情報共有サービスを、設定メニュー内の1つのアクセス可能なページに統合することである。
2023年4月、マイクロソフトは今後2年間で29億米ドルを投資し、日本におけるハイパースケールクラウドコンピューティングとAIインフラを増強すると発表した。また、今後3年間で300万人以上にAIスキルを提供することを目標に、日本初のマイクロソフトリサーチアジアラボを開設し、日本政府とのサイバーセキュリティ協力を深めることで、デジタルスキリングプログラムを拡大する。
提供対象
– ソフトウェア
– サービス
– その他のサービス
対象アーキテクチャ
– 自己回帰言語モデル
– 単頭自己回帰言語モデル
– 多頭自己回帰言語モデル
– 自己符号化言語モデル
– バニラ自己符号化言語モデル
– 最適化自己符号化言語モデル
– ハイブリッド言語モデル
– テキスト対テキスト言語モデル
– プリトレーニング・ファインチューニング・モデル
– その他のアーキテクチャ
モダリティ
– テキスト
– コード
– 画像
– ビデオ
– その他のモダリティ
対象アプリケーション
– 情報検索
– 言語翻訳とローカリゼーション
– コンテンツ生成とキュレーション
– コード生成
– カスタマーサービス自動化
– データ分析とビジネスインテリジェンス
– その他のアプリケーション
対象エンドユーザー
– 情報技術(IT)
– ヘルスケア&ライフサイエンス
– 法律事務所
– 製造業
– 教育機関
– 小売
– メディア&エンターテイメント
– その他エンドユーザー
対象地域
– 北米
米国
カナダ
メキシコ
– ヨーロッパ
o ドイツ
イギリス
o イタリア
o フランス
o スペイン
o その他のヨーロッパ
– アジア太平洋
o 日本
o 中国
o インド
o オーストラリア
o ニュージーランド
o 韓国
o その他のアジア太平洋地域
– 南アメリカ
o アルゼンチン
o ブラジル
o チリ
o その他の南米諸国
– 中東・アフリカ
o サウジアラビア
o アラブ首長国連邦
o カタール
o 南アフリカ
o その他の中東・アフリカ
レポート内容
– 地域レベルおよび国レベルセグメントの市場シェア評価
– 新規参入企業への戦略的提言
– 2021年、2022年、2023年、2026年、2030年の市場データをカバー
– 市場動向(促進要因、制約要因、機会、脅威、課題、投資機会、推奨事項)
– 市場予測に基づく主要ビジネスセグメントにおける戦略的提言
– 主要な共通トレンドをマッピングした競合のランドスケープ
– 詳細な戦略、財務、最近の動向を含む企業プロファイリング
– 最新の技術進歩をマッピングしたサプライチェーン動向
無料カスタマイズの提供:
本レポートをご購入いただいたお客様には、以下の無料カスタマイズオプションのいずれかをご提供いたします:
– 企業プロファイリング
o 追加市場プレーヤーの包括的プロファイリング(3社まで)
o 主要企業のSWOT分析(3社まで)
– 地域セグメンテーション
o 顧客の関心に応じた主要国の市場推定、予測、CAGR(注:フィージビリティチェックによる)
– 競合ベンチマーキング
製品ポートフォリオ、地理的プレゼンス、戦略的提携に基づく主要企業のベンチマーキング
1 エグゼクティブ・サマリー
2 序文
2.1 概要
2.2 ステークホルダー
2.3 調査範囲
2.4 調査方法
2.4.1 データマイニング
2.4.2 データ分析
2.4.3 データの検証
2.4.4 リサーチアプローチ
2.5 リサーチソース
2.5.1 一次調査ソース
2.5.2 セカンダリーリサーチソース
2.5.3 前提条件
3 市場動向分析
3.1 はじめに
3.2 推進要因
3.3 抑制要因
3.4 機会
3.5 脅威
3.6 アプリケーション分析
3.7 エンドユーザー分析
3.8 新興市場
3.9 コビッド19の影響
4 ポーターズファイブフォース分析
4.1 供給者の交渉力
4.2 買い手の交渉力
4.3 代替品の脅威
4.4 新規参入の脅威
4.5 競争上のライバル
5 大型言語モデルの世界市場、オファリング別
5.1 はじめに
5.2 ソフトウェア
5.3 サービス
5.3.1 コンサルティング
5.3.2 LLM開発
5.3.3 インテグレーション
5.3.4 LLMファインチューニング
5.3.4.1 完全微調整
5.3.4.2 検索補強型ジェネレーション(RAG)
5.3.4.3 アダプタベースのパラメータ効率チューニング
5.3.5 LLMを利用したアプリ開発
5.3.6 プロンプト・エンジニアリング
5.3.7 サポートとメンテナンス
5.4 その他のサービス
6 世界の大規模言語モデル市場、アーキテクチャ別
6.1 はじめに
6.2 自己回帰言語モデル
6.3 単頭自己回帰言語モデル
6.4 多頭自己回帰言語モデル
6.5 自己符号化言語モデル
6.6 バニラ自己符号化言語モデル
6.7 最適化自己符号化言語モデル
6.8 ハイブリッド言語モデル
6.9 テキスト対テキスト言語モデル
6.10 事前学習-微調整モデル
6.11 その他のアーキテクチャ
7 世界の大規模言語モデル市場、モダリティ別
7.1 はじめに
7.2 テキスト
7.3 コード
7.4 画像
7.5 動画
7.6 その他のモダリティ
8 大規模言語モデルの世界市場、用途別
8.1 はじめに
8.2 情報検索
8.3 言語翻訳とローカリゼーション
8.3.1 多言語翻訳
8.3.2 ローカリゼーションサービス
8.4 コンテンツ生成とキュレーション
8.4.1 ジャーナリズムと記事作成の自動化
8.4.2 クリエイティブ・ライティング
8.5 コード生成
8.6 カスタマーサービスの自動化
8.6.1 チャットボットとバーチャルアシスタント
8.6.2 セールスとマーケティングの自動化
8.6.3 パーソナライズされたレコメンデーション
8.7 データ分析とビジネスインテリジェンス
8.7.1 センチメント分析
8.7.2 ビジネスレポートと市場分析
8.8 その他のアプリケーション
9 大規模言語モデルの世界市場、エンドユーザー別
9.1 はじめに
9.2 情報技術(IT)
9.3 ヘルスケア&ライフサイエンス
9.4 法律事務所
9.5 製造業
9.6 教育
9.7 小売業
9.8 メディア&エンターテインメント
9.9 その他のエンドユーザー
10 大型言語モデルの世界市場、地域別
10.1 はじめに
10.2 北米
10.2.1 米国
10.2.2 カナダ
10.2.3 メキシコ
10.3 ヨーロッパ
10.3.1 ドイツ
10.3.2 イギリス
10.3.3 イタリア
10.3.4 フランス
10.3.5 スペイン
10.3.6 その他のヨーロッパ
10.4 アジア太平洋
10.4.1 日本
10.4.2 中国
10.4.3 インド
10.4.4 オーストラリア
10.4.5 ニュージーランド
10.4.6 韓国
10.4.7 その他のアジア太平洋地域
10.5 南米
10.5.1 アルゼンチン
10.5.2 ブラジル
10.5.3 チリ
10.5.4 その他の南米地域
10.6 中東・アフリカ
10.6.1 サウジアラビア
10.6.2 アラブ首長国連邦
10.6.3 カタール
10.6.4 南アフリカ
10.6.5 その他の中東・アフリカ地域
11 主要開発
11.1 契約、パートナーシップ、提携、合弁事業
11.2 買収と合併
11.3 新製品上市
11.4 事業拡大
11.5 その他の主要戦略
12 会社プロファイル
12.1 AI21ラボ
12.2 アリババ
12.3 アマゾン
12.4 アンソロピック
12.5 百度
12.6 コヒーレ
12.7 クラウドワークス
12.8 グーグル
12.9 ファーウェイ
12.10 メタ
12.11 マイクロソフト
12.12 ネイバー
12.13 NEC
12.14 OpenAI
12.15 テクノロジー・イノベーション・インスティテュート(TII)
12.16 テンセント
12.17 ヤンデックス
表一覧
1 大規模言語モデルの世界市場展望、地域別(2021-2030年) ($MN)
2 大規模言語モデルの世界市場展望、オファリング別(2021-2030年) ($MN)
3 大規模言語モデルの世界市場展望、ソフトウェア別 (2021-2030) ($MN)
4 大型言語モデルの世界市場展望、サービス別 (2021-2030) ($MN)
5 大型言語モデルの世界市場展望、コンサルティング別 (2021-2030) ($MN)
6 大型言語モデルの世界市場展望、LLM開発別 (2021-2030) ($MN)
7 大型言語モデルの世界市場展望、統合別 (2021-2030) ($MN)
8 大規模言語モデルの世界市場展望、LLM微調整別 (2021-2030) ($MN)
9 大型言語モデルの世界市場展望、フルファインチューニング別 (2021-2030) ($MN)
10 大規模言語モデルの世界市場展望、検索補強生成(RAG)別 (2021-2030) ($MN)
11 大規模言語モデルの世界市場展望、アダプタベースのパラメータ効率チューニング別 (2021-2030) ($MN)
12 大規模言語モデルの世界市場展望、LLMベースのアプリ開発別 (2021-2030) ($MN)
13 大型言語モデルの世界市場展望、プロンプトエンジニアリング別 (2021-2030) ($MN)
14 大型言語モデルの世界市場展望、サポート・メンテナンス別 (2021-2030) ($MN)
15 大型言語モデルの世界市場展望、その他の提供サービス別 (2021-2030) ($MN)
16 大型言語モデルの世界市場展望、アーキテクチャ別 (2021-2030) ($MN)
17 大型言語モデルの世界市場展望、自己回帰言語モデル別 (2021-2030) ($MN)
18 大型言語モデルの世界市場展望、単頭自己回帰言語モデル別 (2021-2030) ($MN)
19 大型言語モデルの世界市場展望、多頭自己回帰言語モデル別 (2021-2030) ($MN)
20 大型言語モデルの世界市場展望、自動エンコード言語モデル別 (2021-2030) ($MN)
21 大型言語モデルの世界市場展望、バニラ自動符号化言語モデル別 (2021-2030) ($MN)
22 大型言語モデルの世界市場展望、最適化自動エンコード言語モデル別 (2021-2030) ($MN)
23 大型言語モデルの世界市場展望、ハイブリッド言語モデル別 (2021-2030) ($MN)
24 大型言語モデルの世界市場展望、テキスト対テキスト言語モデル別 (2021-2030) ($MN)
25 大型言語モデルの世界市場展望、プレトレーニング-ファインチューニングモデル別 (2021-2030) ($MN)
26 大型言語モデルの世界市場展望、その他のアーキテクチャ別 (2021-2030) ($MN)
27 大規模言語モデルの世界市場展望、モダリティ別 (2021-2030) ($MN)
28 大規模言語モデルの世界市場展望、テキスト別 (2021-2030) ($MN)
29 大規模言語モデルの世界市場展望、コード別 (2021-2030) ($MN)
30 大規模言語モデルの世界市場展望、画像別 (2021-2030) ($MN)
31 大型言語モデルの世界市場展望、動画別 (2021-2030) ($MN)
32 大型言語モデルの世界市場展望、その他のモダリティ別 (2021-2030) ($MN)
33 大型言語モデルの世界市場展望、用途別 (2021-2030) ($MN)
34 大規模言語モデルの世界市場展望、情報検索別 (2021-2030) ($MN)
35 大型言語モデルの世界市場展望、言語翻訳とローカライゼーション別 (2021-2030) ($MN)
36 大型言語モデルの世界市場展望、多言語翻訳別 (2021-2030) ($MN)
37 大型言語モデルの世界市場展望、ローカライゼーションサービス別 (2021-2030) ($MN)
38 大型言語モデルの世界市場展望、コンテンツ生成とキュレーション別 (2021-2030) ($MN)
39 大型言語モデルの世界市場展望、自動ジャーナリズムと記事作成別 (2021-2030) ($MN)
40 大型言語モデルの世界市場展望、クリエイティブライティング別 (2021-2030) ($MN)
41 大型言語モデルの世界市場展望、コード生成別 (2021-2030) ($MN)
42 大型言語モデルの世界市場展望、顧客サービス自動化別 (2021-2030) ($MN)
43 大型言語モデルの世界市場展望、チャットボットとバーチャルアシスタント別 (2021-2030) ($MN)
44 大型言語モデルの世界市場展望、販売・マーケティングオートメーション別 (2021-2030) ($MN)
45 大型言語モデルの世界市場展望、パーソナライズされたレコメンデーション別 (2021-2030) ($MN)
46 大型言語モデルの世界市場展望、データ分析・ビジネスインテリジェンス別 (2021-2030) ($MN)
47 大規模言語モデルの世界市場展望、センチメント分析別 (2021-2030) ($MN)
48 大型言語モデルの世界市場展望、ビジネスレポートと市場分析別 (2021-2030) ($MN)
49 大型言語モデルの世界市場展望、その他の用途別 (2021-2030) ($MN)
50 大型言語モデルの世界市場展望、エンドユーザー別 (2021-2030) ($MN)
51 大型言語モデルの世界市場展望:情報技術(IT)別 (2021-2030) ($MN)
52 大型言語モデルの世界市場展望:ヘルスケア・ライフサイエンス別 (2021-2030) ($MN)
53 大型言語モデルの世界市場展望:法律事務所別 (2021-2030) ($MN)
54 大型言語モデルの世界市場展望、製造業別 (2021-2030) ($MN)
55 大型言語モデルの世界市場展望:教育別 (2021-2030) ($MN)
56 大型言語モデルの世界市場展望:小売業別 (2021-2030) ($MN)
57 大型言語モデルの世界市場展望:メディア&エンターテインメント別 (2021-2030) ($MN)
58 大型言語モデルの世界市場展望:その他のエンドユーザー別 (2021-2030) ($MN)
注:北米、欧州、APAC、南米、中東・アフリカ地域の表も上記と同様に表現しています。
❖本調査資料に関するお問い合わせはこちら❖